Buffer 是 Node.js 的内置类型,它是用来表示内存中一块区域的,它保存的是二进制数据,可以将它看做为一个二进制数组。
Buffer 可以用来表示图片、视频这样的二进制数据,另外我们从文件中读取到的也是 Buffer 类型的数据,从网络中接收的数据也是 Buffer 类型的数据,所以学习 Buffer 还是很有必要的。
Buffer 位于全局作用域中,所以不需要通过 require('buffer') 来引入 Buffer。
创建 Buffer 对象
alloc
我们可以通过 Buffer.alloc(size, [fill], [encoding]) 来分配一个 size 字节大小的内存,还可以接收两个可选参数
- fill:使用 fill 来填充 Buffer 中的每一个字节
- encoding:如果 fill 为字符串,那么使用 encoding 来对字符串进行编码为二进制
当不指定 fill 参数,默认为填充 0。
const buf1 = Buffer.alloc(5); |
我们还可以使用 allocUnsafe(size) 来分配指定大小的内存,不过不会默认填充 0,其中的内容不确定
const buf = Buffer.allocUnsafe(5); |
我们可以通过 fill(fill, encoding) 方法为 Buffer 对象填充指定值
const buf = Buffer.allocUnsafe(5); |
from
我们也可以通过 Buffer.from() 方法来创建一个 Buffer 对象,from 方法可以接收的参数包括数组,字符串,Buffer 对象,对象等类型。
接收一个整形数组,数组中的整数应该在 0~255 之间,超出此范围的数字将会被截断
const buf = Buffer.from([1, 2, 3, 4, 5]); |
我们还可以像其中传入一个字符串,并指定编码,它会使用指定编码将字符串编码为二进制,如果不指定编码的话,默认为编码为 utf-8
const buf = Buffer.from("hello", "utf-8"); |
from 方法还可以接收一个 Buffer 对象,它会拷贝传入的 Buffer 对象中的数据到新的 Buffer 对象中
const buf1 = Buffer.from("hello", "utf-8"); |
from 方法还可以接收一个对象,当传入对象,首先会将对象转化为原始值,然后根据原始值转化为对应的二进制数组
let obj = { |
Buffer 对象的属性
length
通过 length 属性可以知道 Buffer 数组的长度
const buf = Buffer.from("Hello World!"); |
buffer
Buffer 对象内部实际存储数据的是一个 ArrayBuffer 的对象,通过 buffer 属性可以得到这个对象
const buf = Buffer.alloc(5); |
读 Buffer 对象
本节介绍如何访问 Buffer 对象中的内容。
下标
在文章的开头提过,我们可以将 Buffer 对象看做是一个二进制数组,既然是数组,那么就可以通过下标的形式来访问数组中的内容。
const buf = Buffer.from([1, 2, 3, 4, 5]); |
它们会以补码的形式解析字节,返回对应的数字。
readXxx
我们还可以通过 buf.readInt8() buf.readInt16() buf.readUint8() buf.readUint16() 等方法来访问 Buffer 对象中的内容。
const buf = Buffer.from([1, 2, 3, 4, 5]); |
迭代器
Buffer 对象的迭代器同数组的迭代器相同,也有三个迭代器,分别是
- entries
- keys
- values
我们通过遍历迭代器来访问 Buffer 对象中的内容。
const buf = Buffer.from([3, 4, 2]); |
for (let key of buf.keys()) { |
for (let value of buf.values()) { |
写 Buffer 对象
本小节讲解如何向 Buffer 对象中写入内容。
下标
我们可以直接通过下标来改变 Buffer 对象中的内容
const buf = Buffer.from([1, 2, 3]); |
write
我们可以通过 write(string, [offset], [length], [encoding]) 方法向 Buffer 中写入字符串:
- string:表示要写入的字符串
- offset:偏移量,即跳过 offset 个字节开始写入,默认为 0
- length:要写入的最大字节数,不超过
buf.length - offset,默认值为buf.length - offset - encoding:指定编码,默认为
utf-8
该方法返回已写入的字节数。
const buf = Buffer.from([1, 2, 3, 4]); |
writeXxx
同 readXxx,我们可以通过 writeInt8() 方法向 buf 中写入数据,方法接收两个参数:
- value:要写入的值
- offset:偏移量,默认为 0
const buf = Buffer.alloc(5); |
踩坑:没有
writeInt16(),不过有writeInt16BE()与writeInt16LE(),分别代表以大端序、小端序写入
其他方法
isBuffer
该方法接收一个对象,用来判断该对象是不是一个 Buffer 对象
let obj1 = {}; |
isEncoding
该方法接收一个代表编码的字符串,返回 Buffer 是否支持该种编码,如果支持则返回 true,否则返回 false
console.log(Buffer.isEncoding("utf-8")); // true |
slice
slice(start, end) 可以裁切原有的 Buffer 对象,返回一个新的 Buffer 对象,其中 start 和 end 代表裁切的起始位置和结束位置,左闭右开 [start, end),这两个参数是可选的,start 默认为 0,end 默认为 buf.length。返回的 Buffer 对象与原先对象引用的是同一块内存,即它们的 buffer 属性是一样的。
const buffer = Buffer.from("hello world!"); |
subarray
subarray(start, end) 几乎可以看做等同于 slice 方法了,二者的语义不同,不过行为确实一致的,subarray 的语义表示返回原数组的某个范围的子数组,而 slice 的语义表示的裁切。同样 subarray 返回新的 Buffer 对象,并且返回的 Buffer 对象的 buffer 与原 Buffer 对象的 buffer 属性是相同的。
const buffer = Buffer.from("hello world!"); |
copy
copy(target, [targetStart], [sourceStart], [sourceEnd]) 方法是将 source 从 sourceStart 到 sourceEnd 的内容复制到 target 从 targetStart 的位置,见下动图
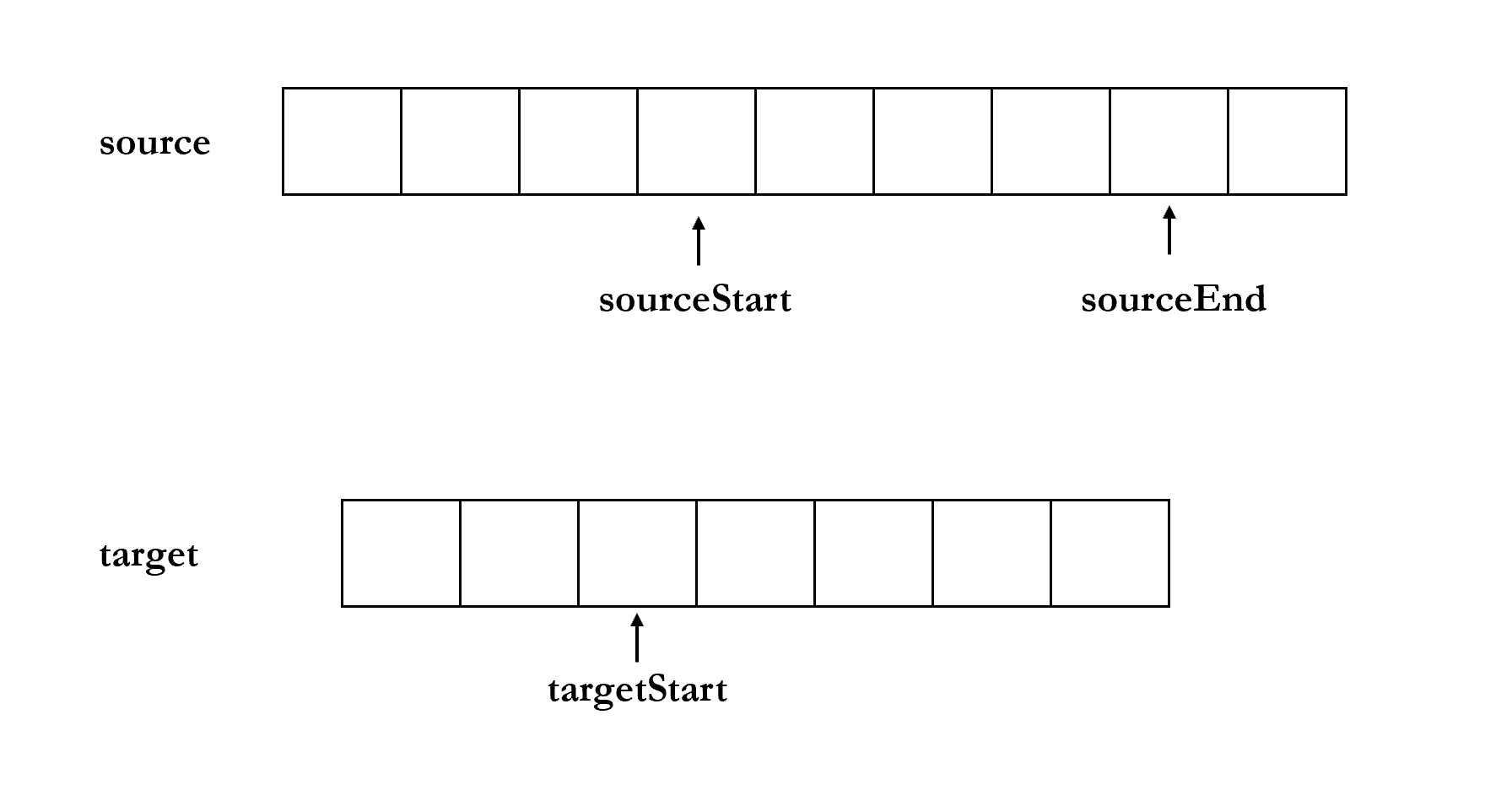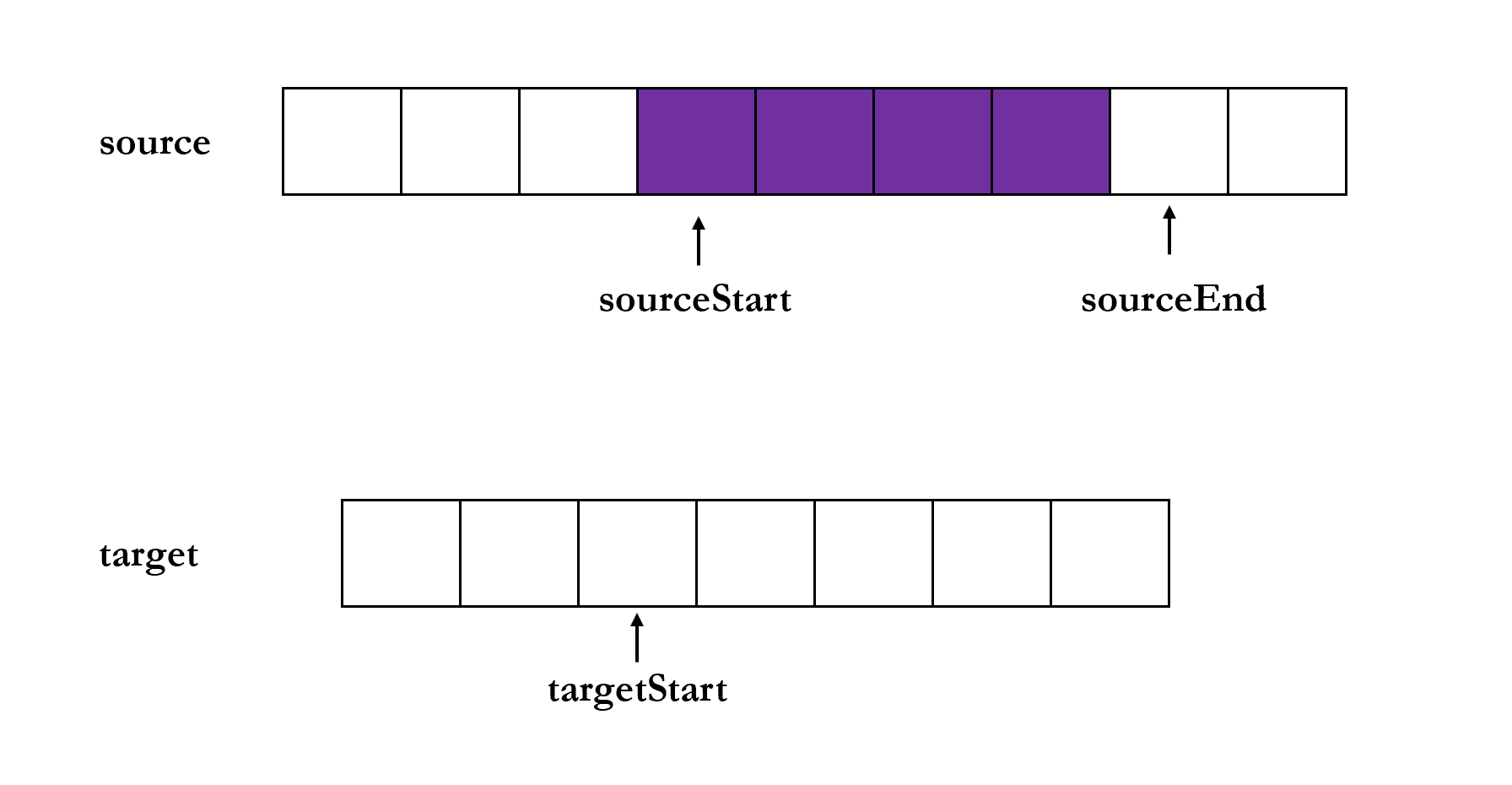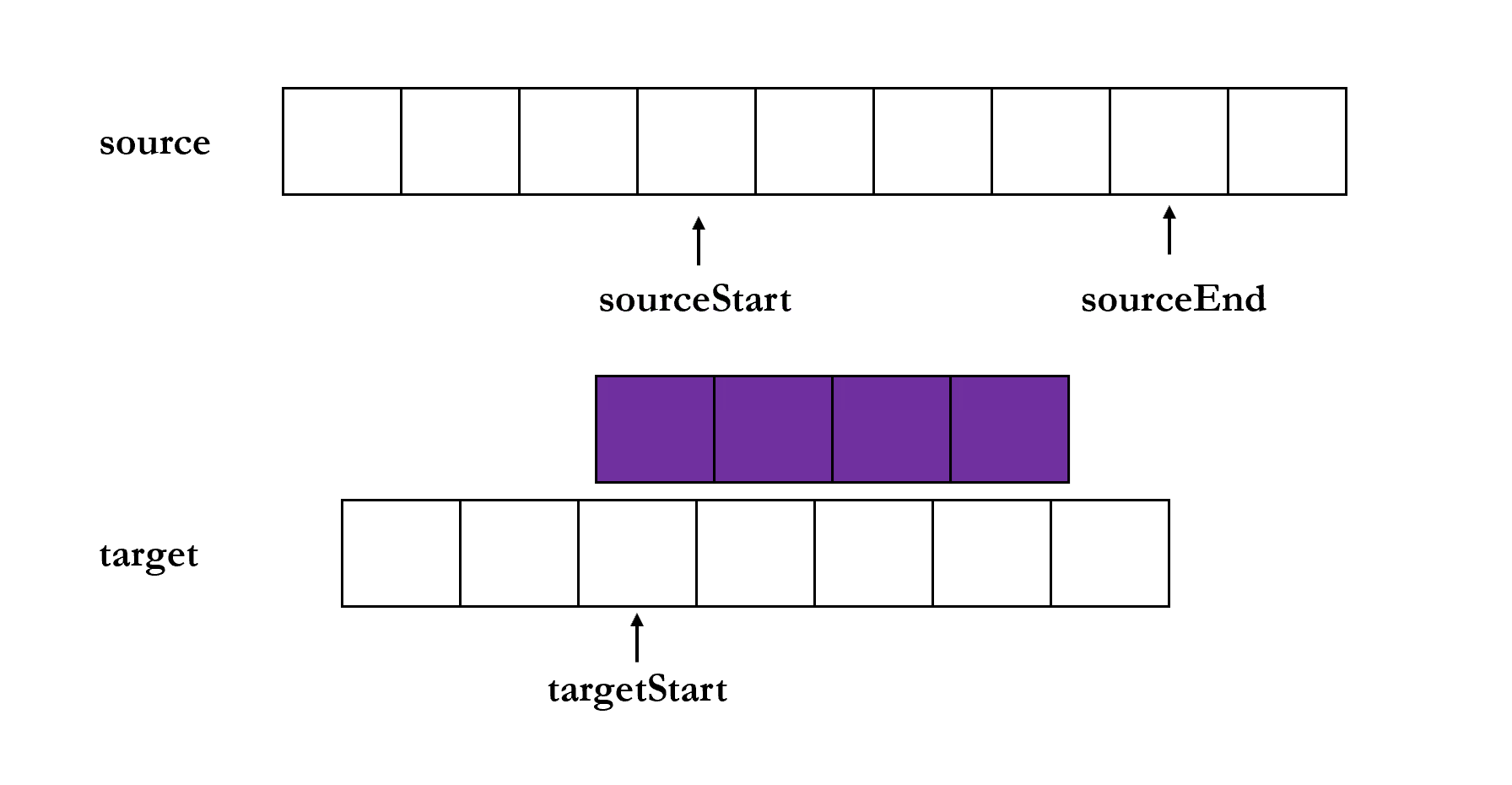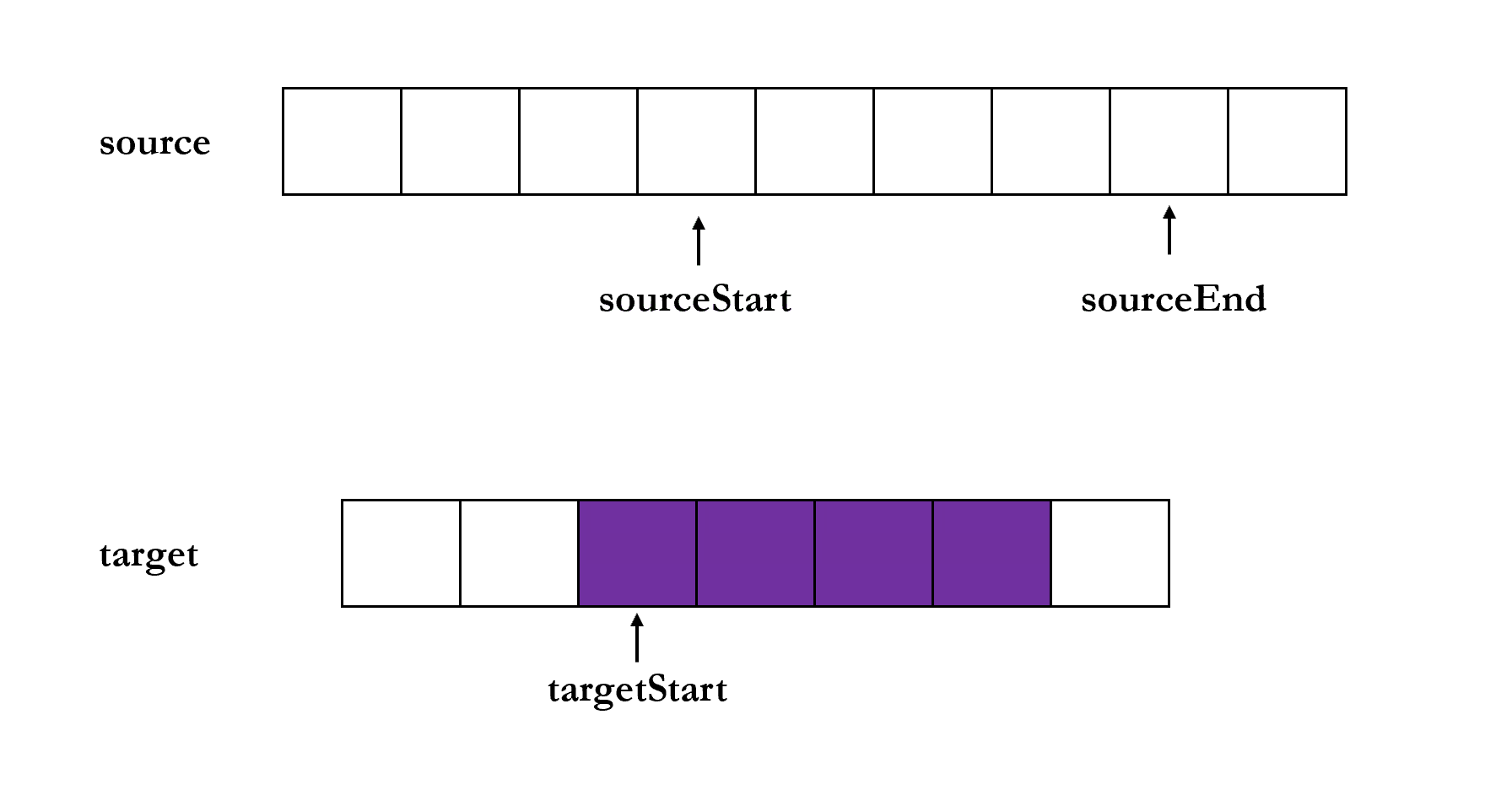
除了 target 以外,其他三个参数都是可选参数,targetStart 与 sourceStart 的默认值为 0,sourceEnd 的默认值为 buf.length.
const buf1 = Buffer.from("HelloWorld"); |
includes
buf.includes(value, [offset], [encoding]) 方法的作用是判断 value 是否在 buf 中。
value 可以是一个字符串,也可以是一个 Buffer 对象,也可以是一个整数;offset 用来规定查找范围,表示从 offset 处开始查找,默认为 0;enconding 表示编码,默认为 utf-8。
const buf = Buffer.from("HelloWorld"); |
indexOf
buf.indexOf(value, [offset], [encoding]) 是用来查找 value 在 buf 中的下标的,参数的含义同 includes 方法相同,如果在 buf 找不到 value,那么会返回 -1,所以 includes(value) 方法其实就相当于 indexOf(value) !== -1
const buf = Buffer.from("HelloWorld"); |
equals
buf.equals(otherBuffer) 是比较两个 Buffer 对象的字节是否完全相同,如果相同,则返回 true,否则返回 false
const buf1 = Buffer.alloc(5); |
参考文献
 微信
微信 支付宝
支付宝




