
在字符串的处理中,我们经常要进行字符串的匹配,校验等等操作。比如校验字符串的格式是否符合邮箱,电话号码的格式,校验密码是否符合要求,密码中是否包含数字和字母等等;又或者匹配得到某种规则的字符串。这一些操作如果使用常规的方法进行字符串操作,会花费较大的代价,包括时间和精力。
正则表达式是用来表达字符串的规则,它可以检验字符串是否符合某个特定的规则,或者匹配字符串中符合规则的字符,在一般的使用中,正则表达式一般用来匹配字符串中的字符或者字符串中特定的位置。
正则对象
JavaScript 正则对象的创建有两种常见的方法,一是使用 RegExp 构造函数进行创建,二是使用字面量的方法进行创建,如下
let regex1 = new RegExp('hello', 'g');
let regex2 = /hello/g;
其中 hello 表示字符串的规则,用来匹配字符串中的"hello",g 表示进行全局匹配(global),像这样的标志还有两个,m 表示进行多行匹配(multiline),i 表示忽略大小写(ignoreCase),这三个标志互不冲突,可以同时使用,如
let regex = /hello/igm;
具体标志的作用在后面讲解。在实际的使用中,我们一般会使用字面量的形式创建正则对象,相对于使用构造函数,字面量的创建比较简便,不过如果需要动态的创建正则对象,或者根据字符串创建正则对象,那么可以考虑使用构造函数的方式。
正则对象中的属性
global:布尔值,是否设置了g标志ignoreCase:布尔值,是否设置了i标志lastIndex:整数,从字符串的某个位置开始匹配,默认为0multiline:布尔值,是否设置了m标志source:正则表达式的字符串表示
let regex = /\d{3}hello$/ig;
console.log(regex.global); // true
console.log(regex.ignoreCase); // true
console.log(regex.multiline); // false
console.log(regex.lastIndex); // 0
console.log(regex.source); // \d{3}hello$
正则对象中的方法
test
test(),该方法接收一个字符串参数,返回一个布尔值,用来判断该字符串是否符合正则对象的规则,如下
let regex = /hello/g;
let string1 = "hello world";
let string2 = "Hello World";
console.log(regex.test(string1)); // true
console.log(regex.test(string2)); // false
exec
exec() 方法是用来捕获匹配到的字符,该方法接收一个字符串,返回一个数组,数组的第一项表示与整个模式匹配的字符串,第二项表示第一个捕获组(捕获组的概念如果不懂,可以看了括号的作用在回来看),第三项表示第二个捕获组,以此类推。返回的数组与普通数组不同的是,该数组还有三个属性,index 、 input 和 groups,index 表示匹配到的字符在原始字符串中的位置,从 0 开始;input 表示输入的原始字符串,groups 表示捕获组的名称。
let regex = /(he)(ll)(o)/g;
let string = "so hello";
let result = regex.exec(string);
console.log(result);
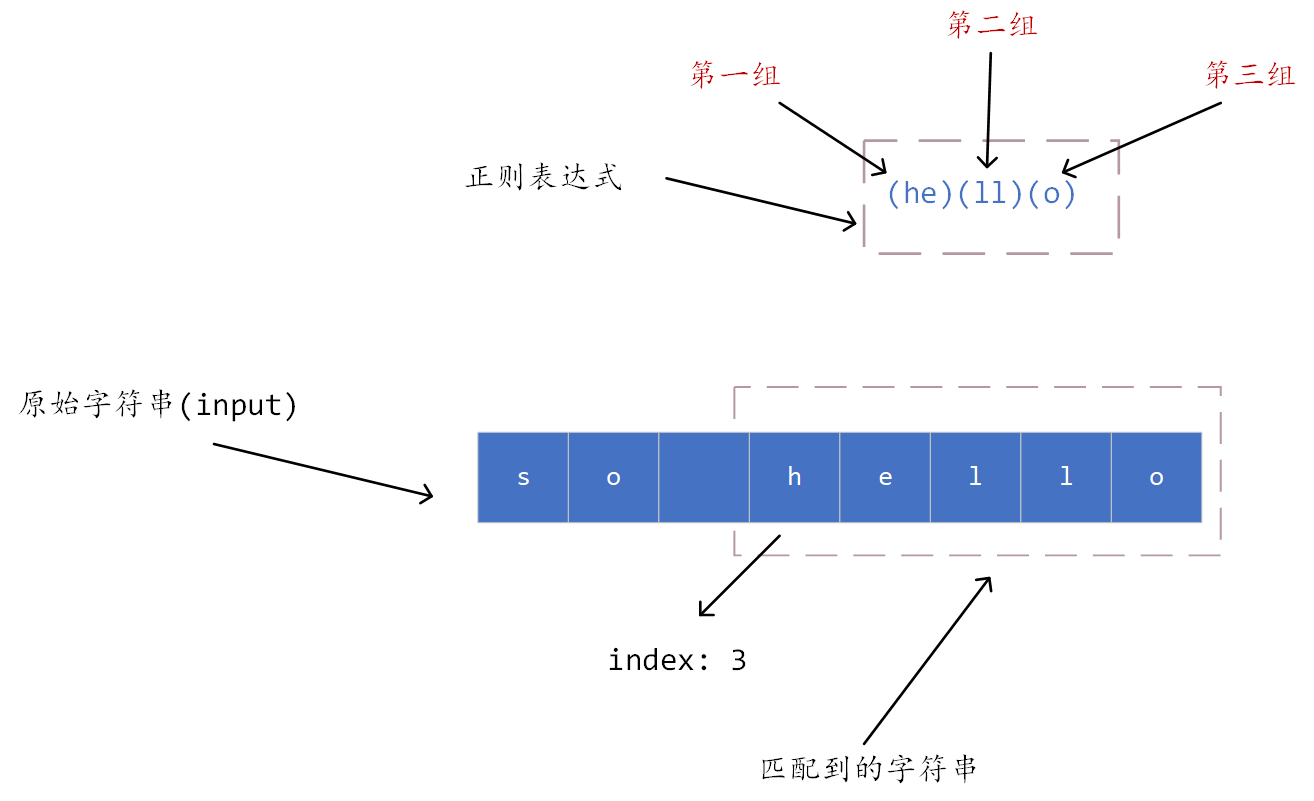
输出为
[
'hello',
'he',
'll',
'o',
index: 3,
input: 'so hello',
groups: undefined
]
如果正则对象的标志有 g 的话,那么在执行 exec() 方法后会改变 lastIndex 为匹配字符串后字符的 index,接下来再次执行 exec() 方法时将会从 lastIndex 处开始匹配,如
let string = "ab abc abc";
let regex = /ab/g;
console.log(regex.lastIndex); // 0
regex.exec(string);
console.log(regex.lastIndex); // 2
regex.exec(string);
console.log(regex.lastIndex); // 5
regex.exec(string);
console.log(regex.lastIndex); // 9
regex.exec(string); // 匹配不到会返回 null
console.log(regex.lastIndex); // 重新变为 0
构造函数RegExp的属性
构造函数 RegExp 中有一些静态属性,这些属性会保存最近一次正则对象操作的一些信息,并且这些属性有两种方法访问,一种是具有语义的长属性名,一种是简短的短属性名,具体如下:
input:短属性名为$_,最近一次要匹配的字符串lastMatch:$&,最近一次的匹配项leftContext:$`,input中lastMatch的左边部分rightContext:$',input中lastMatch的右边部分$1, $2, ...:后面介绍
let regex = /hello/g;
let string = "he hello llo";
regex.exec(string);
console.log(RegExp.input); // he hello llo
console.log(RegExp.lastMatch); // hello
console.log(RegExp.leftContext); // he_ (从_表示空格)
console.log(RegExp.rightContext); // _llo
字符串方法
在字符串中,有许多的方法也是与正则表达式有关的,如 replace,match,下面就简单介绍一下。
replace
replace() 方法的作用是使用新的字符串替换字符串中的某些内容,该方法接收两个参数,第一个参数表示字符串中要被替换的内容,它可以是一个具体的字符串或者是一个正则对象,第二个参数为一个字符串,这个参数是用来替换第一个参数的,如
let string = "gello";
string = string.replace('g', 'h'); // 将 string 中的 g 替换为 h
console.log(string); // hello
let string = "abc";
string = string.replace(/[ab]/g, '#'); // 将字符串中的 a 或 b 替换为 #
console.log(string); // ##c
在上面中使用了 [ab],这个表示 a 或者 b,具体会在元字符那里讲解。
match
match 方法的作用与 exec 的作用差不多,不过一个是 RegExp 对象的方法,一个是 String 对象的方法。match 方法接收一个正则对象,它返回一个数组,根据正则对象是否设置了 g 标志,返回的结果也不相同。
如果没有设置 g 标志,即不会全局匹配,只会匹配一次,那么它返回的结果与 exec 返回的结果相同,数组的第一个元素表示匹配的字符串,后面的元素表示捕获组,并且也有 input,index,groups等属性,表示的含义也痛 exec,如下
let string = "hello";
let result = string.match(/(?<h>he)(?<l>ll)(o)/);
console.log(result);
输出为
[
'hello',
'he',
'll',
'o',
index: 0,
input: 'hello',
groups: [Object: null prototype] { h: 'he', l: 'll' }
]
这次的正则表达式跟以往的不同,这次我设置了捕获组的名称,如
(?<h>he)
即将捕获组 (he) 的名称设置为了 h,设置捕获组名称的格式如下
(?<捕获组名称>捕获组内容)
为捕获组设置名称,可以方便在后面进行引用。
如果设置了 g 标志,这时返回值与 exec 方法就不同了,它会将字符串中所有符合正则表达式规则的内容都匹配出来,并放入数组中,如
let string = "hello";
let re = /(?<h>he)(?<l>ll)(o)/g;
let result = string.match(re);
console.log(result); // [ 'hello' ]
string = "hello helloworld";
result = string.match(re);
console.log(result); // [ 'hello', 'hello' ]
这时设置的捕获组的信息就提取不到了,所以从某种程度上说,exec 的功能比 match 更加的强大,不过 exec 并不能一次提取出字符串中所有符合规则的内容,而是需要做一个循环,如下
let string = "hello helloworld";
let re = /(?<h>he)(?<l>ll)(o)/g;
let result;
let results = new Array();
// 当 re.exec()不为 null 时
while (result = re.exec(string)) {
results.push(result[0]); // result 中还包含了捕获组的信息
}
console.log(results); // [ 'hello', 'hello' ]
字符匹配
上面使用正则表达式进行匹配都是进行精确的匹配,如 /hello/,匹配字符串中的 hello 内容,这样我们根本无法领会到正则表达式的强大,正则表达式正是强大在它模糊匹配的能力,比如我们在 Windows 中进行文件查找,有时我们不记得文件的具体名称,比如忘了某个字母,这个时候我们会用 . 去表示任意的字母去进行查找。现在我们就来讲讲正则表达式模糊匹配的能力。
字符组
在进行匹配的时候,如果我们不确定某个位置的字符是什么,我们可以使用表示特定含义的字符来占据这个位置,比如 [abc] 表示这个位置是 a,b,c 中的某个字符。如果我们想表示这个字符是小写字母,按照上面的写法,你可能会这么写 [abcdefghijklmnopqrstuvwxyz],这样的写法有点反人类,我们可以使用范围表示法来代替上面的写法,如 [a-z] 的写法就表示所有的小写字母,同理 [A-Z] 就表示所有的大写字母,[0-9] 就表示数字,[0-9a-zA-Z] 表示这个位置可以是数字,小写字母,大写字母。如下
let re = /[a-zA-Z0-9]/;
console.log(re.test('0')); // true
console.log(re.test('s')); // true
console.log(re.test('S')); // true
console.log(re.test('?')); // false
我们可以在 [] 中加入 ^ 表示取反,如 [^0-9] 表示非数字,即它可以匹配所有的非数字
let re = /[^0-9]/;
console.log(re.test("2")); // false
console.log(re.test("a")); // true
console.log(re.test("?")); // true
我们还可以使用元字符来占据位置,比如 \d 就代表数字,它的作用与 [0-9] 是一样的,常见的元字符如下所示(不包含表示位置的元字符,表示位置的元字符在后面介绍)
| 元字符 | 含义 |
|---|---|
\d | 表示数字 |
\s | 表示空白字符,包括空格,回车,制表符等等 |
\w | 表示数字,大小写字母和下划线,相当于 [0-9a-zA-Z_] |
. | 表示任意一个字符 |
来看几个例子
// 表示数字
let re1 = /\d/;
console.log(re1.test("2")); // true
// 空白字符
let re2 = /\s/;
console.log(re2.test(" ")); // true
console.log(re2.test("\t")); // true
console.log(re2.test("\n")); // true
// 表示大小写字母,数字和下划线
let re3 = /\w/;
console.log(re3.test("2")); // true
console.log(re3.test("a")); // true
console.log(re3.test("A")); // true
console.log(re3.test("_")); // true
与在 [] 中加入 ^表示取反,上面的元字符也有对应的元字符表示取反的概念
| 元字符 | 含义 |
|---|---|
\D | 与 \d 相反,表示非数字 |
\S | 与 \s 相反,表示非空白字符 |
\W | 与 \w 相反,表示非单词 |
let re1 = /\D/;
console.log(re1.test("2")); // false
console.log(re1.test("\n")); // true
let re2 = /\S/;
console.log(re2.test(" ")); // false
console.log(re2.test("9")); // true
let re3 = /\W/;
console.log(re3.test("0")); // false
console.log(re3.test("\t")); // true
量词
现在我们假设使用正则表达式去匹配电话号码,假设电话号码就是 11 位数字,所以写出来的正则表达式是这样的 \d\d\d\d\d\d\d\d\d\d\d,这种写法也相当的反人类,不仅难读(需要一个个数才知道有多少个数),而且写起来也麻烦,我们可以使用量词来简写上面的表达式,如 \d{11} 就表示 \d 连续出现 11 次,常见的量词写法如下
| 量词 | 含义 |
|---|---|
{n} | 表示连续出现 n 次 |
{m,n} | 表示连续出现 m-n,最少出现 m,最多出现 n 次 |
{n,} | 表示连续出现最少 n 次(包括 n 次) |
* | 表示连续出现任意多次 |
+ | 表示连续出现 1 次或 1 次以上 |
? | 表示出现 0 次或 1 次 |
// 匹配连续出现的 5 位数字
let re = /\d{5}/g;
let string = "123 1234 12345 654321";
console.log(string.match(re)); // [ '12345', '65432' ]
// 匹配连续出现的 2-3 位数字
let re = /\d{2,3}/g;
let string = "12 123 1234";
console.log(string.match(re)); // [ '12', '123', '123' ]
// 匹配连续出现 4 位及 4 位以上的数字
let re = /\d{4,}/g;
let string = "12 123 1234 12345";
console.log(string.match(re)); // [ '1234', '12345' ]
// b 可以出现任意次
let re = /ab*c/g;
let string = "ac abc abbc abbbc";
console.log(string.match(re)); // [ 'ac', 'abc', 'abbc', 'abbbc' ]
// b 出现 1 次或 1 次以上
let re = /ab+c/g;
let string = "ac abc abbc abbbc";
console.log(string.match(re)); // [ 'abc', 'abbc', 'abbbc' ]
// b 出现 0 次或 1 次
let re = /ab?c/g;
let string = "ac abc abbc abbbc";
console.log(string.match(re));
贪婪匹配与惰性匹配
所谓的贪婪匹配就是尽可能的多匹配,如
let re = /ab+/g;
let string = "abbbb";
console.log(string.match(re)); // [ 'abbbb' ]
明明匹配 ab 也可以,但是它会尽可能多的匹配,这就是贪婪模式,与此相对的是惰性匹配,惰性匹配就是在满足条件的情况下会尽可能的少匹配,如上例就会匹配 ab,在默认的情况下是贪婪匹配,要使用惰性匹配就要使用惰性量词
| 贪婪 | 惰性 |
|---|---|
+ | +? |
* | *? |
? | ?? |
{n,m} | {n,m}? |
{n,} | {n,}? |
let re = /ab+?/g;
let string = "abbbb";
console.log(string.match(re)); // [ 'ab' ]
现在考虑根据 html 字符串获得某 id 属性,如 <div id="container" class="active"></div>,如果我们使用贪婪匹配的话,考虑这样的匹配规则 /id=".*"/,那么捕获到的并不是我们想要的
let re = /id=".*"/;
let string = "<div id=\"container\" class=\"active\"></div>";
console.log(re.exec(string)[0]); // id="container" class="active"
我们发现匹配到的是 id="container" class="active",因为在贪婪模式下再符合条件的情况下会尽可能多的匹配,所以会直接匹配到最后一个双引号,解决办法有两种,其中简单的解决办法就是使用惰性匹配
let re = /id=".*?"/;
let string = "<div id=\"container\" class=\"active\"></div>";
console.log(re.exec(string)[0]); // id="container"
另一种办法就比较 trick,我觉得只可意会,难以言传
let re = /id="[^"]*"/;
let string = "<div id=\"container\" class=\"active\"></div>";
console.log(re.exec(string)[0]); // id="container"
仔细体会上面的写法吧,我觉得很好用,比如获得某标签的标签名
let re = /<[^>]*>/;
let string = "<div></div>";
console.log(re.exec(string)[0]); // <div>
分支
有时候我们需要在多个分支之间进行选择,比如匹配十六进制表示的颜色,有两种表示,一种是 #F4E242 六位的,一种是简写的 #FFF 三位表示的,我们可以使用 | 来表示或的关系
let regex = /#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g;
let string1 = "#FFF";
let string2 = "#F34E23"
console.log(string1.match(regex)); // [ '#FFF' ]
console.log(string2.match(regex)); // [ '#F34E23' ]
括号的作用
分组与分支
假设我们要匹配 I love Java 和 I love C 这两句话,你可能会写出这样的正则表达式
/I love Java|C/
但是这个正则表达式表示的是 I love Java 或者 C 而不是 I love C,正确的写法应该是这样
/I love (Java|C)/
Java 和 C 选其一。
捕获数据
假设我们要匹配一个格式为 yyyy-mm-dd 格式的日期,并且希望获得年月日,那么可能会这么写
let re = /\d{4}-\d{2}-\d{2}/;
let string = "2020-05-27";
let result = re.exec(string)[0]; // 2020-05-27
let results = result.split("-");
console.log("year:" + results[0]); // year:2020
console.log("month:" + results[1]); // month:05
console.log("day:" + results[2]); // day:27
其实我们可以通过添加括号来捕获数据,对于被括号包起来的数据,其匹配的内容会被提取出来,添加到返回的数组中,如
let re = /(\d{4})-(\d{2})-(\d{2})/;
let string = "2020-05-27";
let result = re.exec(string);
console.log("year:" + result[1]); // 第一个捕获组 \d{4} 匹配的内容
console.log("month:" + result[2]); // 第二个捕获组 \d{2} 匹配的内容
console.log("day:" + result[3]); // 第三个捕获组 \d{2} 匹配的内容
上面我们对年月日的规则使用括号包了起来,在进行匹配时,对应被匹配到的数据会添加到数组中,在介绍 exec 方法时,其返回的数组,第一个元素表示匹配到的字符串,后面的元素表示捕获组(括号包起来)中捕获的内容。
RegExp的属性$1...
除了可以根据返回的数组 result 来得到捕获的数据,还可以通过在上面提过一嘴的 RegExp 构造函数的属性 $1, $2, $3 ... 等等来获得所捕获的内容,其中 $1 表示第一个捕获组所匹配的内容,如下
let re = /(\d{4})-(\d{2})-(\d{2})/;
let string = "2020-05-27";
let result = re.exec(string);
console.log("year:" + RegExp.$1); // year:2020
console.log("month:" + RegExp.$2); // month:05
console.log("day:" + RegExp.$3); // day:27
每次在使用正则表达式进行匹配时,RegExp 中的 $1, $2, $3 ... 也会相应的更新。
括号嵌套
现在考虑如果括号有嵌套的情况,比如上面日期格式捕获更精准的表达式
/(\d{4})-((0[1-9])|(1[0-2]))-((0[1-9])|([1-2]\d)|(3[0-1]))/
上面括号嵌套的很复杂,在原理上,被括号包起来的规则所匹配的内容都会被捕获,那么嵌套带来的问题就是,捕获的顺序哪个在前,哪个在后,其实也很简单,根据左括号来,比如上式中的捕获顺序为
(\d{4})((0\d)|(1[0-2]))(0\d)(1[0-2])((0[1-9])|([1-2]\d)|(3[0-1]))(0[1-9])([1-2]\d)(3[0-1])
所以如果使用上面的正则表达式进行捕获得到年月日的信息,根据分析年是第一捕获组,月是第二捕获组,日是第五捕获组
let re = /(\d{4})-((0[1-9])|(1[0-2]))-((0[1-9])|([1-2]\d)|(3[0-1]))/;
let date = "2020-05-27";
let result = re.exec(date);
console.log(result[1], result[2], result[5]); // 2020 05 27
由于无用的捕获组太多,导致想要提取包含信息的捕获组获取困难,其实仔细观察,里面的大多数括号主要是为分支做准备的,对于这些捕获组,我们可以考虑不捕获,仅仅作为分支使用,我们在括号里面的前方加入 ?: 表示该括号匹配的内容不进行捕获,如下
let re = /(\d{4})-((?:0[1-9])|(?:1[0-2]))-((?:0[1-9])|(?:[1-2]\d)|(?:3[0-1]))/;
let date = "2020-05-27";
let result = re.exec(date);
console.log(result[1], result[2], result[3]); // 2020 05 27
如果作为分支的括号太多,为每一个分支添加 ?: 也比较费力,那么可以考虑给包含信息的捕获组命名,命名的方法在上面有提到过
let re = /(?<year>\d{4})-(?<month>(0[1-9])|(1[0-2]))-(?<day>(0[1-9])|([1-2]\d)|(3[0-1]))/;
let date = "2020-05-27";
let result = re.exec(date);
let groups = result.groups;
console.log(groups.year, groups.month, groups.day); // 2020 05 27
通过给捕获组命名,可以方便的通过 groups 对象得到想要的数据。
反向引用
现在再次考虑匹配日期,已知下面这三种日期格式都可以
2017-02-12
2017 02 12
2017/02/12
所以你可能会写出这样的正则表达式
/\d{4}(-| |\/)\d{2}(-| |\/)\d{2}/
经过测试,发现能符合要求
console.log(re.test("2017-02-17")); // true
console.log(re.test("2017 02 17")); // true
console.log(re.test("2017/02/17")); // true
但是你会发现一些意外的情况
console.log(re.test("2017-02/17")); // true
console.log(re.test("2017-02 17")); // true
console.log(re.test("2017 02-17")); // true
前后的分隔符不一致的情况也能够匹配,而我们要求的是前后的分隔符是一样的,这个时候我们可以通过引用分组,使得前面和后面的分隔符是一样的,如下
let re = /\d{4}(-| |\/)\d{2}\1\d{2}/;
console.log(re.test("2017-02-17")); // true
console.log(re.test("2017 02 17")); // true
console.log(re.test("2017/02/17")); // true
console.log(re.test("2017-02/17")); // false
console.log(re.test("2017-02 17")); // false
console.log(re.test("2017 02-17")); // false
注意到我们对于后面的分组,我们使用了 \1 去进行替代,\1 的意思就是代表引用第一个分组,这样就可以做到这个地方与前面的分组相同。同理我们也可以使用 \2 表示引用第二个分组(如果有的话,如果没有就单纯的表示匹配字符串 "\2")。
位置匹配
相关元字符
正则表达式中的最后一个内容就是关于位置的匹配,与字符匹配不同,位置匹配时匹配字符间的位置,常见有关位置的元字符如下
| 元字符 | 含义 |
|---|---|
^ | 开头位置 |
$ | 结尾位置 |
\b | 单词边界,即 \w 与 \W 之间的位置 |
(?=p) | 匹配 p 模式前面的位置,具体见例子 |
(?<=p) | 匹配 p 模式后面的位置 |
let string = "[JS] hello";
let result = string.replace(/^/,"#");
console.log(result); // #[JS] hello
result = string.replace(/$/, "#");
console.log(result); // [JS] hello#
result = string.replace(/\b/g, "#"); // \b 是 \w 与 \W 之间的位置,表示单词的边界
console.log(result); // [#JS#] #hello#
result = string.replace(/(?=hello)/, "#"); // hello 前面的位置
console.log(result); // [JS] #hello
result = string.replace(/(?<=hello)/, "#"); // hello 后面的位置
console.log(result); // [JS] hello#
同理,也有元字符表示与上面相反的意义
| 元字符 | 含义 |
|---|---|
\B | 与 \b 相反,表示非单词边界 |
(?!p) | 与 (?=p) 相反,表示不是 p 前面位置的所有位置 |
(?<!p) | 与 (?<=p) 相反,表示不是 p 后面位置的所有位置 |
let string = "[JS] hello";
let result = string.replace(/\B/g,"#");
console.log(result); // #[J#S]# h#e#l#l#o
result = string.replace(/(?!hello)/g, "#"); // 不是 hello 前面位置的所有位置
console.log(result); // #[#J#S#]# h#e#l#l#o#
result = string.replace(/(?<!hello)/g, "#"); // 不是 hello 后面位置的所有位置
console.log(result); // #[#J#S#]# #h#e#l#l#o
千位分隔符案例
现在来做一个案例,将数字转化为千位分隔符表示法,如 12345678 转化为 12,345,678,我们首先找到后三位数字的前面位置,然后添加逗号,如下
let string = "12345678";
result = string.replace(/(?=(\d{3})$)/g,",");
console.log(result); // 12345,678
进一步弄出所有的逗号
result = string.replace(/(?=(\d{3})+$)/g,","); // 12,345,678
但是还是有一个小小问题,测试的数字个数是三的倍数的时候,在开头也会添加一个逗号
let string = "123456789";
result = string.replace(/(?=(\d{3})+$)/g,",");
console.log(result); // ,123,456,789
我们可以修改正则表达式如下
result = string.replace(/(?=(?!^)(\d{3})+$)/g,",");
其中 (?!^) 表示不是开头的位置。如果希望支持更多的格式,比如 1234567 12345678 转换为 1,234,567 12,345,678,只要将上面的表达式中的开头,结尾替换为 \b 即可
let string = "1234567 12345678";
result = string.replace(/(?=(?!\b)(\d{3})+\b)/g,",");
console.log(result); // 1,234,567 12,345,678
考虑到 (?!\b) 就相当于 \B,所以上面的表达式也可简写如下
/(?=\B(\d{3})+\b)/g
多行模式
正则表达式有三个常见的标志,分别为全局模式 g,表示进行全局匹配,如果不设置该标志,那么只会匹配一次,如果字符串后面还要符合规则的字符串,是不会被匹配的,对于 exec() 方法,非全局模式下不会更改 lastIndex,即 lastIndex 始终是 0。
let string = "hello hello";
let re1 = /hello/;
let re2 = /hello/g;
// 非全局替换 只会替换匹配到的第一个 hello
console.log(string.replace(re1, "#")); // # hello
// 全局替换 字符串中所以的 hello 都会被替换
console.log(string.replace(re2, "#")); // # #
第二标志 i 很好理解,即忽略大小写
let re1 = /hello/;
let re2 = /hello/i;
let string = "Hello";
// 不忽略大小写
console.log(re1.test(string)); // false
// 忽略大小写
console.log(re2.test(string)); // true
第三个标志 m 表示多行模式,它只会影响 ^,$,如果不是多行模式,那么 ^, $ 就表示字符串的开头和结尾,如果是多行模式,那么 ^,$ 就表示每一行的开头和结尾。
非多行模式
let string = "I \nlove \njava";
// 非多行 ^,$ 表示字符串的开头和结尾
console.log(string.replace(/^|$/g, "#"));
输出如下
#I
love
java#
多行模式
let string = "I \nlove \njava";
// 多行模式 ^,$ 表示每一行的开头和结尾
console.log(string.replace(/^|$/gm, "#"));
输出如下
#I #
#love #
#java#